扩容 Kafka 集群
Kafka 在蓝鲸架构中,用于数据上报通道的队列缓存。在数据链路中,生产者是 GSE 组件的 gse_data 进程,将 agent 上报的监控时序数据或者日志采集数据 写入到 kafka 集群。消费者是监控后台的 transfer 进程,将队列中的数据消费,清洗,并入库到相应存储中。
本教程描述了如何在蓝鲸社区版中扩容 Kafka 集群。
- 要使一个副本集能提供足够的冗余,至少需要部署三个 Broker ,所以新增节点数必须为偶数,至少增加两台机器。
- 官方的扩容指引:https://kafka.apache.org/0100/documentation.html#basic_ops_cluster_expansion
- Kafka 扩容集群很简单,只需要分配一个唯一的 Broke id 即可加入集群
- 扩容完成后,新的 Broker 中如果没有新增 Topic,这个节点是不会承载任何数据,所以需要用户手动迁移老的数据到新的 broker,以达到集群内均匀的负载分布。具体操作参考官方文档说明:https://kafka.apache.org/0100/documentation.html#basic_ops_cluster_expansion
- 单机版部署的蓝鲸只有单 Kafka 集群,建议扩容至 3 个 Broker,实现容错和高可用性
1. Kafka 扩容
1.1. 使用标准运维流程扩容
1.1.1. 前置准备
- 机器准备
- 建议 Kafka 独占机器部署,配置不低于 4C16G,采用 SSD 硬盘或 IO 较高的磁盘组合
- 官方建议的生产环境配置要求:https://kafka.apache.org/documentation/#hwandos
实现免密
开始部署前,请确保新增主机跟中控机已实现免密。1
ssh-copy-id <ip>
请先前往节点管理,对新增主机进行 agent 安装
将需要部署产品的标准运维流程模版导入至标准运维
标准运维流程模版 下载
详细步骤:打开标准运维 -> 流程 -> 项目流程 -> 导入YAML -> 点击上传 -> 导入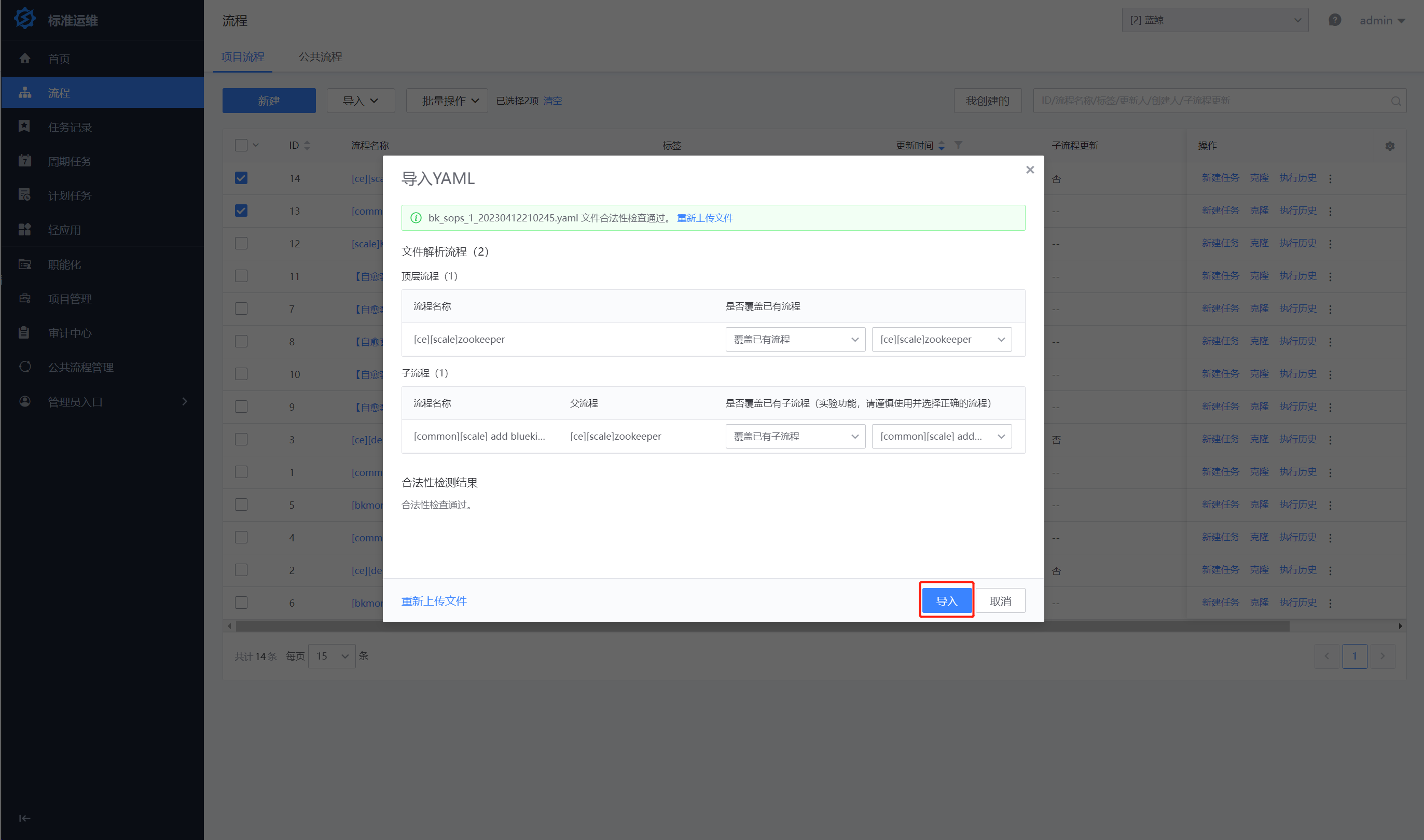
1.1.2. 执行扩容操作
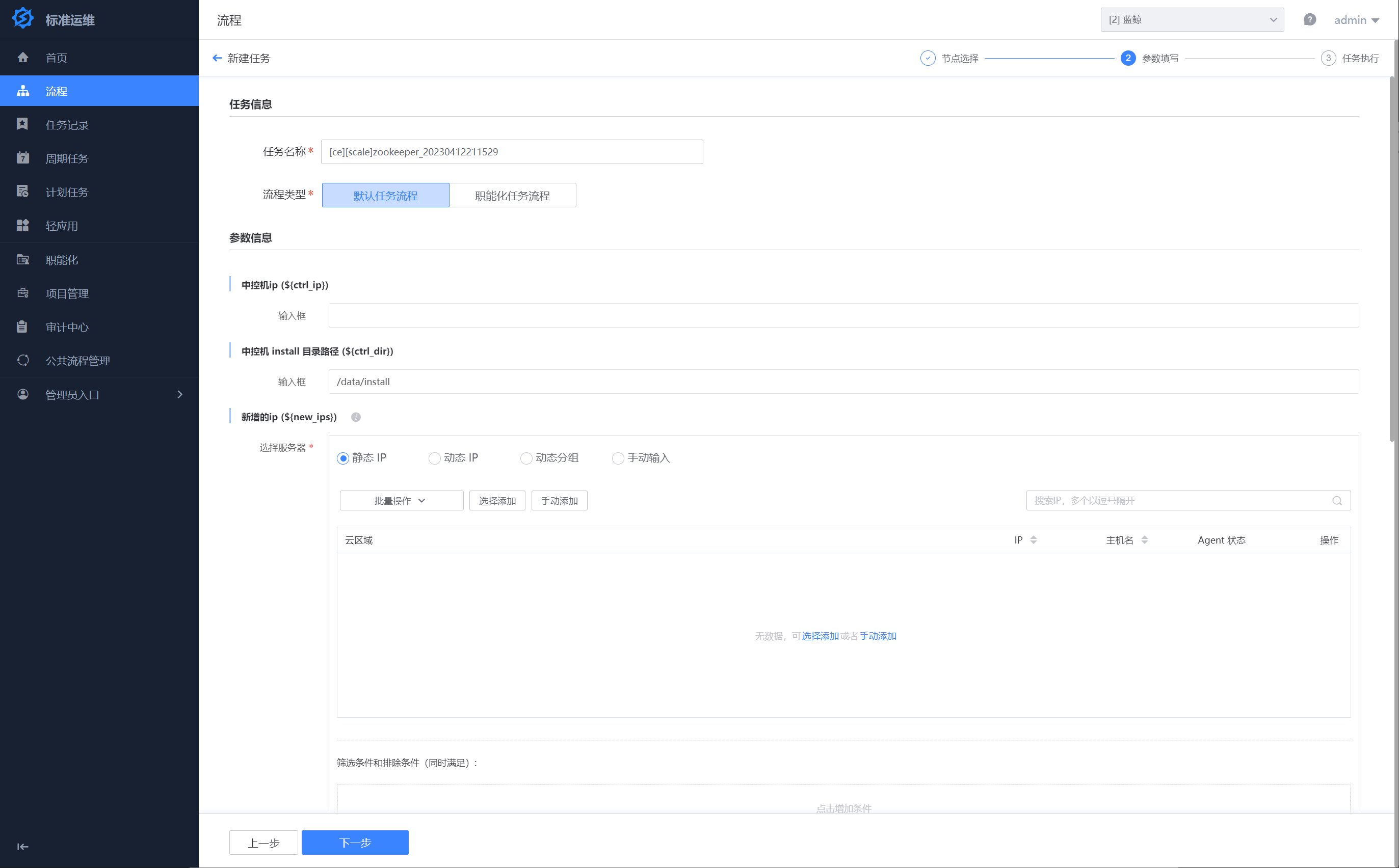
- 选择流程 “[ce][scale]kafka” 流程模版进行新建任务,根据提示填写相关信息。确认填写信息无误后,开始执行任务。
- 点击下一步进入到“参数信息”填写页,按需填入参数
1.2. 手动单步扩容
- 机器准备
- 建议 Kafka 独占机器部署,配置不低于 4C16G,采用 SSD 硬盘或 IO 较高的磁盘组合
- 官方建议的生产环境配置要求:https://kafka.apache.org/documentation/#hwandos
1.2.1. 准备机器:新增并初始化机器
以下初始化步骤以单个机器为例,如有多台扩容机器,请多次重复执行,注意替换机器 IP
以下操作在中控机执行,默认在 /data/install 下执行
配置新机器免密
1
ssh-copy-id <ip>
同步蓝鲸的 yum repo
1
rsync -av /etc/yum.repos.d/Blueking.repo root@<ip>:/etc/yum.repos.d/
在 install.config 中增加扩容的机器和模块定义
1
2
3cat >> install.config <<EOF
<ip> kafka(config)
EOF执行蓝鲸的机器初始化操作
1
2
3
4
5
6
7
8
9
10
11# 同步脚本至新机器
./bkcli sync common
# 执行初始化脚本
pcmd -H <ip> '/data/install/bin/init_new_node.sh'
# 确认新机器成功加入了 consul 集群,如果没有输出,可以再次重试
consul members | grep "<ip>:"
# 同步 java8 安装包
./sync.sh zk /data/src/java8.tgz /data/src
1.2.2. 执行扩容操作
如有多台扩容机器,一下操作请多次重复执行,注意替换机器 IP
以下操作在新增机器上执行,默认在 /data/install 下执行
登陆新增机器
1
ssh <ip>
安装 JAVA
1
/data/install/bin/install_java.sh -p /data/install -f /data/src/java8.tgz
安装 Kafka 并配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# 默认数据目录
DATA_DIR="/data/bkce/public/kafka"
# 安装 Kafka
if ! rpm -ql kafka &>/dev/null; then
yum -y install kafka
fi
# 创建目录并配置权限
install -d -o kafka -g kafka "$DATA_DIR"
# 选取一台现有 Broker,拷贝配置至新增节点
rsync -av <现有Broker的ip>:/etc/kafka/server.properties /etc/kafka/server.properties
# 获取最后一个 broker.id
zookeepercli -servers <zk-ip:2181> -c ls /common_kafka/brokers/ids | sort -n | tail -1
# 修改配置中 broker.id 定义,id 在 kafka 集群中必须保持唯一
sed -i -r "/^broker.id=/s/[0-9]+/<broker.id>/" /etc/kafka/server.properties
# 修改配置中内网 ip 地址
sed -i -r "/^listeners=/s/([0-9]+\.){3}[0-9]+/<新机器的ip>/" /etc/kafka/server.properties启动新增 Broker 的 Kafka 服务
1
2
3
4systemctl enable --now kafka
# 确认服务状态
systemctl status kafka
1.2.3. 注册 consul:kafka.service.consul
1 | cd /data/install ; source utils.fc; source tools.sh |
1.2.4. 完成扩容,验证产品功能
略
1.2.5 注册蓝鲸业务拓扑
以 “Kafka” 为例:
- 打开“配置平台” > “蓝鲸” 业务 > 选中新增的机器 > 点击“追加至” > “业务模块”

- 选择“公共组件” > “kafka” > “下一步”

- 确认变更内容 > “确认追加”

扩容 Kafka 集群